SA
SA  KW
KW  IE
IE AU
AU UAE
UAE UK
UK USA
USA  CA
CA DE
DE  QA
QA ZA
ZA  BH
BH NL
NL  MU
MU FR
FR 









AI can do a lot, but even the smartest systems need a little context to work properly.
If you are trying to figure out how to develop a RAG application, you’ve probably noticed this problem already. AI sounds smart, until it doesn’t. Ask something recent or too specific, and suddenly it starts guessing.
That is the gap RAG (Retrieval-Augmented Generation) fills. Rather than using pre-trained knowledge alone, it draws real and relevant information and then forms a response. So the answers are not only fluent. They are actually present.
Businesses around the world are looking for smarter ways to leverage their data. Building an AI-powered search app can cost between $40,000 and $200,000. No matter where you are in the world, even in the US, working with a trusted mobile app development company in USA makes sure your app is smart, reliable, and ready to use.
Also Read – RAG vs. Fine-Tuning vs. Prompt Engineering: Optimizing Large Language
In this guide, we will explore how to develop a RAG application, from understanding the basics to designing the architecture, setting up retrieval systems, integrating vector databases, and building pipelines for AI-powered applications.
What is RAG and How It Works?
Retrieval-Augmented Generation, abbreviated as RAG, is a way to make AI more reliable by letting it use external information instead of depending only on what it was trained on. In simple terms, it doesn’t just “remember”, it actually looks things up before answering.
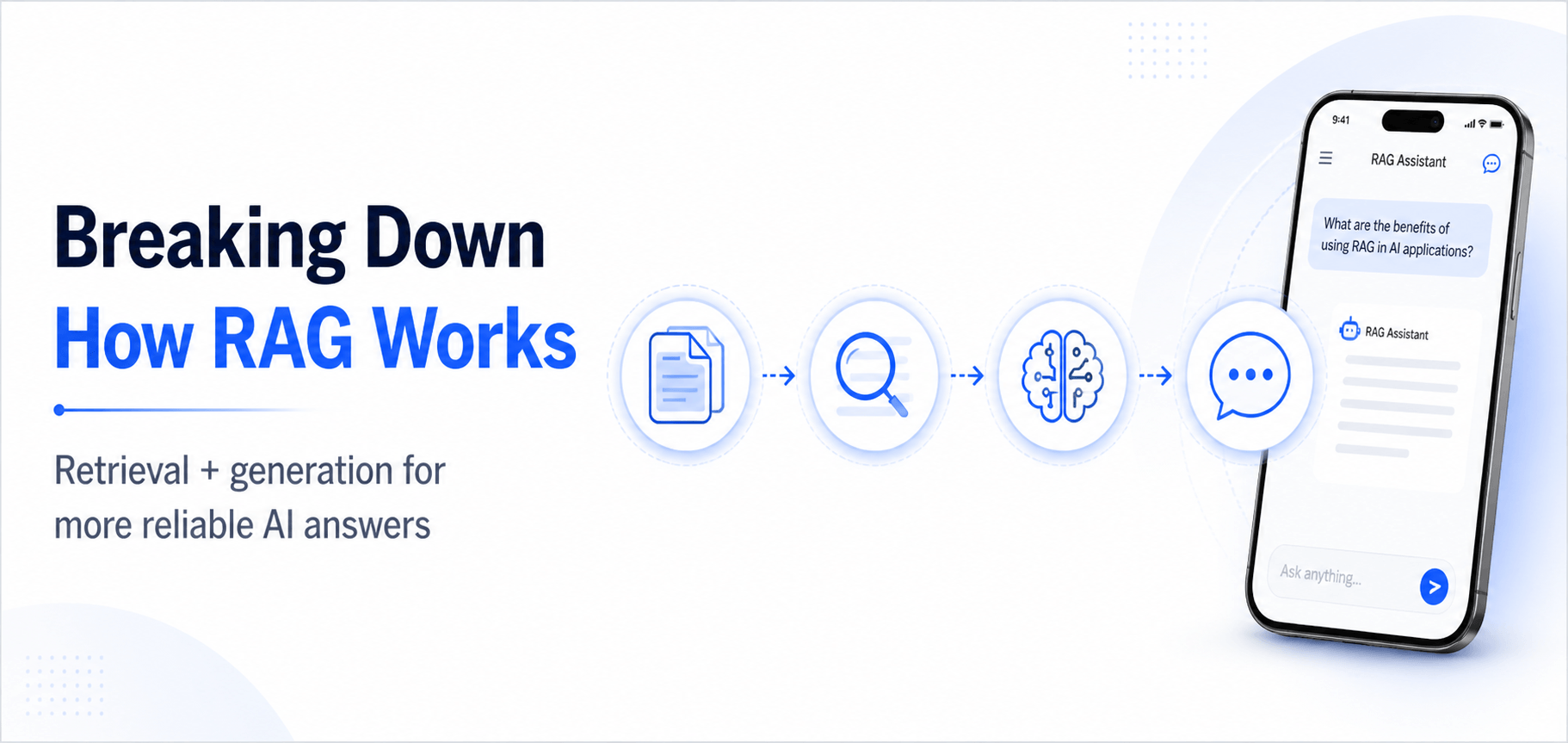
RAG combines two powerful components:
1. A retrieval system that pulls in relevant information from external sources, using smart LLM retrieval systems to find what actually matters.
2. A large language model (LLM) that takes this context and turns it into a clear, accurate response.
Think about it for a second. If you had to answer a tricky question, would you rely only on memory or quickly look it up first? That is exactly how RAG works.
Now, unlike traditional AI (which basically relies on pre-trained knowledge), RAG fetches up-to-date context, reducing errors and making the system smarter and more relevant.
Before We Compare…
Before we get into the comparison, it’s important to understand that RAG is not just a small upgrade.
It modifies the way AI approaches the answer to the questions in general. The traditional models are entirely reliant on what they were trained and this implies that they have a fixed amount of knowledge that can either become outdated or incomplete with time.
RAG, however, brings a more dynamic methodology. It does not just rely on the stored knowledge, but actively searches for pertinent information each time a query is posed. The difference between the responses in terms of accuracy, context sensitivity, and reliability is noticeable with this shift.
Traditional AI vs. RAG-Based Systems: What is the Difference?
Now, to really see the difference, let’s break it down side by side.
| Aspect | Traditional AI | RAG-Based Systems |
| Knowledge Source | Pre-trained data only | External + real-time data |
| Accuracy | Can be inconsistent | More reliable and grounded |
| Handling Updates | Struggles with recent info | Easily adapts to new data |
| Response Style | Fluent but sometimes incorrect | Context-aware and relevant |
| Flexibility | Limited | Highly adaptable |
Concisely, RAG changes when the AI chooses to think.
Traditional systems answer first and hope it works out. RAG postpones that time. It provides a disjuncture between the question and the answer, and then takes advantage of it to locate context.
All the heavy lifting is being done by that pause.
Since at this point, it is no longer the memory taking the test. It follows the system, having obtained an opportunity to be grounded in something real. And that is why the output is different, although you may not be able to say why at that moment.
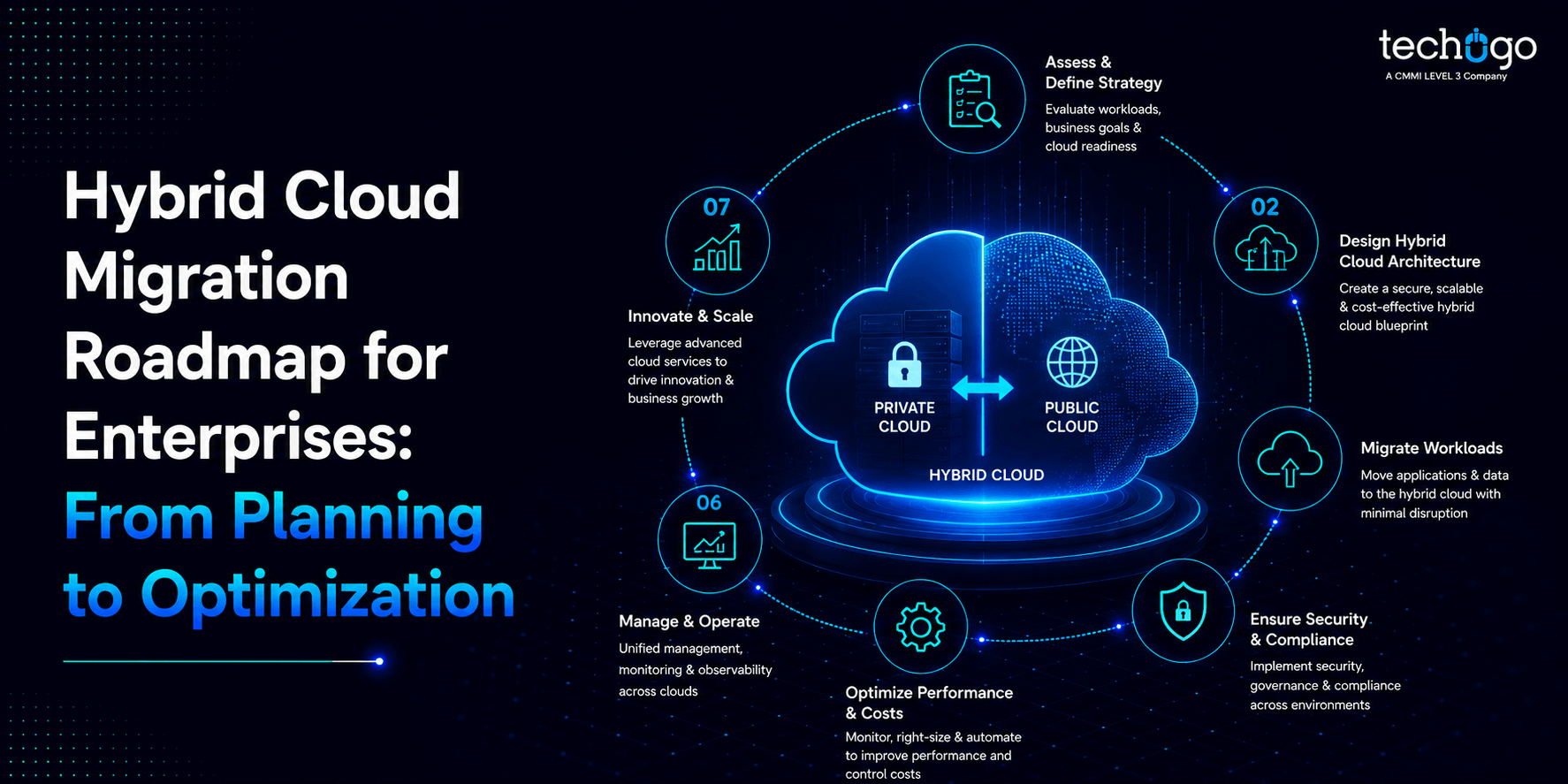
How to Develop a RAG Application, Step by Step
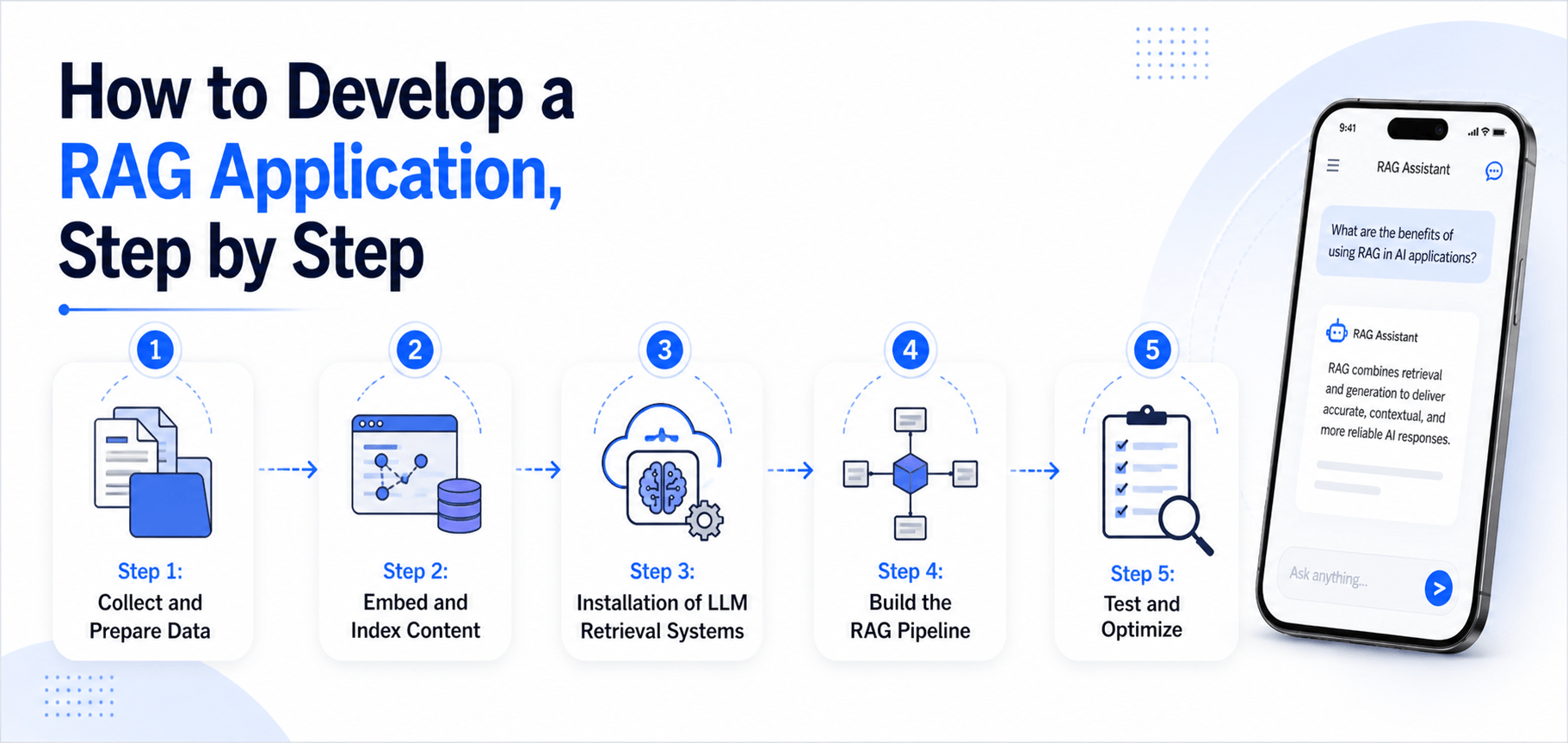
Here’s a clear, step-by-step workflow for building your own RAG system:
Step 1: Collect and Prepare Data
Before anything else, you need to gather the raw material that your RAG system will work with. This includes all relevant documents, FAQs, knowledge bases, support tickets, or any internal reports that could help answer user queries. Don’t just dump everything together. Take time to clean and organize the data. Remove duplicates, outdated information, and irrelevant content.
Next, break large documents into smaller, manageable chunks. Why? Because smaller, well-defined pieces of information make it easier for the system to embed and retrieve context later. Think of it like chopping up ingredients before cooking, you want everything ready and in the right size so the process runs smoothly. Proper preparation at this stage sets the foundation for your RAG pipeline steps and ensures the AI has high-quality information to work with.
Step 2: Embed and Index Content
After having your data ready, it is time to convert this information into something that the AI can read: vectors. With the help of embeddings, every piece of content is transformed into a numerical value that reflects its semantic content. These vectors are then put in a database of vectors, which is the foundation of vector database integration for RAG systems.
This is essential since it enables the AI to carry out semantic search (information search directed by meaning rather than search based on keywords). E.g., a user may ask, How do I reset my password, despite your document saying, Password recovery steps. The use of the search in vectors guarantees that the AI still retrieves the appropriate content. Proper indexing here, too, accelerates retrieval, thereby making your system faster and more efficient.
Step 3: Installation of LLM Retrieval Systems
It is time to connect your data to the actual AI now. Upon a query input, the system is able to transform the query into a vector and scan your vector database to find the most relevant documents. This is where the power of the LLM retrieval systems comes in. They make the AI look at the correct context rather than make a guess.
These retrieved documents are then fed to the large language model, which produces an accurate, contextual, and human-readable response. Think about the AI as a smart assistant that reads the necessary information and only then talks, rather than using just memory. This is what contributes to RAG being much more dependable than the older AI systems that merely respond and wish it were right.
Step 4: Build the RAG Pipeline
Everything is prepared; now it is time to put it together into a functioning workflow. RAG pipeline steps involve all stages, such as data ingestion, indexing of vectors and query embedding, query retrieval, generation, and lastly output formatting.
Imagine a well-oiled machine: different parts convey information to each other. A single step is sluggish or out of time, and the entire system becomes clumsy. Proper RAG architecture design will mean that all the steps can communicate effectively, therefore queries are responded to promptly, correctly, and contextually.
Step 5: Test and Optimize
At last, no system is perfect on the first try. Begin testing your RAG application using real-world queries. Monitor mistakes, interpretation mistakes, or inappropriate responses. Refine your embeddings, control retrieval options, and change document chunking or indexing.
This is an iterative process that enhances accuracy and efficiency, making the system more reliable to the end-users. Frequent optimization ensures that your LLM retrieval systems and vector databases keep running smoothly as your data increases or evolves. As time goes by, your AI-powered search applications will become more responsive, intelligent, and able to process more complex and nuanced queries.
RAG Architecture Design Essentials
The proper design of the RAG architecture will guarantee the scalability and reliability of your system. Key components include:
- Retriever: Identifies valuable content fast.
- Vector Database: This is where semantic search embeddings are stored.
- LLM (Large Language Model): Responds like humans.
- Orchestration Layer: Makes a seamless connection between all components.
Good architecture ensures that your RAG application is fast, responsive, and easy to maintain.
Technology Stack for AI-Powered Search Applications
In creating AI-driven search applications using RAG, the technology stack is the core. All components (including the storage of data and the production of answers) must be compatible.
Let’s break down the essential components and why they matter.
1. Vector Databases: Storing Information Intelligently
The old databases are based on precise keywords that may overlook much information. This is solved by having vector databases, which store content in the form of vectors; numeric values of meaning. This will enable your AI to locate the appropriate content despite the fact that the users might ask questions differently from how they are in your documents.
Pinecone, Weaviate, and FAISS are popular choices. They are quick, scalable, and have been created to process massive data volumes with accuracy. The selection of the appropriate database is determined by your size, speed needs, and options such as metadata search, or a combination of search by keyword and search by a vector.
2. Embedding Models: Making Text Understandable
Your data must be comprehended by the AI before it can utilize your data. Models can be embedded to convert text into high-dimensional vectors representing meaning. It is to make sure that queries such as reset password and recover account refer to the same content.
The most typical options are OpenAI embeddings or Hugging Face models, but domain-specific embeddings can be used. The quality of the embeddings that we provide has a direct influence on the quality of your search results. Embeddings that are poor result in irrelevant answers, whereas good embeddings make your AI appear natural and intelligent.
3. Large Language Models (LLMs): Generating Human-Like Responses
When some relevant content has been retrieved, an LLM takes control. GPT, LLaMA, or Claude produce human-readable, coherent, and clear answers depending on the documents retrieved. This is the one that makes RAG systems appear smart.
The important thing is that the AI is not dependent solely on the memory or pre-training. Rather, it integrates both retrieval and generation and generates correct answers based on your current data. This is the reason why the use of RAG-powered applications is more accurate in the real-world than traditional AI systems.
4. Orchestration Frameworks: Coordination of the System
A RAG system is a system that has several parts operating. Embedding, vector databases, and LLMs are linked through orchestration frameworks such as LangChain or Haystack. They deal with query routing, preprocessing, and caching and ensure that everything is efficient.
Without adequate orchestration, the system would stall, fail to access the appropriate content, or give partial answers. This layer makes the AI always provide prompt and prompt responses.
5. Cloud Infrastructure: Power and Scalability
Intelligent search applications require a stable infrastructure. The computing power, storage, and scalability required by real-time responses are offered by cloud platforms such as AWS, GCP, or Azure. They also sustain graphics-intensive LLM tasks and large query rates.
Cloud infrastructure will keep your system running and doing the same as your data or user base increases. Cloud-based monitoring and logging tools aid in identifying and recording performance problems before they can cause issues for users.
6. Optional Enhancements (Making the System Smarter)
When the foundations are established, you can make improvements to achieve performance and reliability:
- Storing common queries to minimize the load.
- Dashboards to track usage trends and enhance relevance.
- LLM fine-tuning on domain knowledge.
- The security measures to defend confidential information.
These are improvements that do not revamp the stack and make your system more effective, precise, and reliable.
Putting It All Together
Every layer of the stack supports the others. Embeddings make data searchable, vector databases store it efficiently, LLMs generate human-like responses, orchestration keeps everything running smoothly, and cloud infrastructure powers it reliably.
When done right, these components combine to create AI-powered search applications that are fast, accurate, and helpful. Users get meaningful answers, developers have a maintainable system, and businesses can scale without worrying about technical limits.
Unlock Smarter Search with Techugo’s AI-Powered Apps
Apps are everywhere, but an AI-powered search that actually understands your business?
At Techugo, we’re a mobile app development company that builds intelligent apps powered by AI. Basically, apps that understand your users, adapt to their needs, and deliver real business results.
Here’s how we help:
1. Expert Consultation and Strategy
We collaborate with you to establish objectives, design the RAG architecture, and select the appropriate technology stack for your AI-powered search applications.
2. Data Preparation and Management
We structure your documents, questions and answers, knowledge bases, and support tickets, cleanse the data, and cut it into chunks that will be ready to embeddings (so your AI can work with high-quality information).
3. Custom Embeddings and Vector Database Integration
We set up embedding models and integrate vector databases so your AI retrieves the right information efficiently, understanding meaning, not just keywords.
4. LLM Integration and Orchestration
Our team connects large language models with your retrieval system and manages orchestration frameworks like LangChain or Haystack, ensuring seamless communication between all components.
5. Cloud System and Scalability
Your AI-driven search applications run on trusted cloud infrastructure such as AWS, Azure, or GCP, and your RAG system is fast, scalable, and always available.
6. End-to-End Support
Techugo stays with you through planning, development, deployment, and post-launch support, ensuring your AI-powered search applications are maintainable, scalable, and continuously improving.
Give your app the intelligence it deserves. Partner with Techugo to create AI-powered solutions that respond with accuracy, context, and speed.
FAQs
Q1: What is a RAG system?
A: RAG is an abbreviation of Retrieval-Augmented Generation. It involves both the process of looking up the relevant documents in a database and the creation of human responses in a language model. This contributes to more accurate and situational AI responses.
Q2: Why use a vector database in RAG?
A: Vector databases are databases where content is represented as numeric embeddings rather than plain text. This allows your AI to interpret meaning, not only keywords, and thus, queries such as reset my password and recover my account find the correct answers.
Q3: How do embeddings work?
A: Embeddings transform text into high-dimensional vectors, representing meaning. They assist the AI to match user queries with relevant documents even though the wording may be different.
Q4: Do I need a special LLM for RAG?
A: You can work with such popular LLMs as GPT, LLaMA, or Claude. The trick lies in the fact that the LLM processes retrieved material instead of acting on prior knowledge only. Your domain can be fine-tuned to enhance accuracy.
Q5: What is the role of orchestration frameworks like LangChain or Haystack?
A: They are connecting the parts of your RAG system: embeddings, vector database, and LLM. They deal with routing of queries, preprocessing, and caching, and make all of it work efficiently.
Q6: How do I improve the accuracy of my AI-powered search applications?
A: Query testing, embedding fine-tuning, retrieval parameter adjustments, and refinements such as caching, analytics dashboards, and domain-specific LLM fine-tuning should be regularly tested, refined, and launched.
Q7: Are RAG-powered applications secure?
A: Security is based on your infrastructure. Proper access controls, encryption, and compliance should be used to ensure sensitive data is safe without compromising the efficiency of the AI.
Get in touch
We'd love to hear from you.